What an AI Job Actually Costs
Ask what an AI model costs and you get a number like $0.14 or $30 per million tokens. That number tells you almost nothing about what the output costs.
No one buys tokens. They buy a finished landing page, a go-to-market plan, an inbox sorted before they've poured their coffee.
Tokens are flour. You don't eat flour. You eat bread, and the price of the loaf depends on how many times the model kneads it, how much context it re-reads on every pass, and whether the job actually needs a frontier brain or just a competent inexpensive one.
We did the math on three real jobs. The result: model choice, and the freedom to change it, is the line item that matters. The rest is noise.
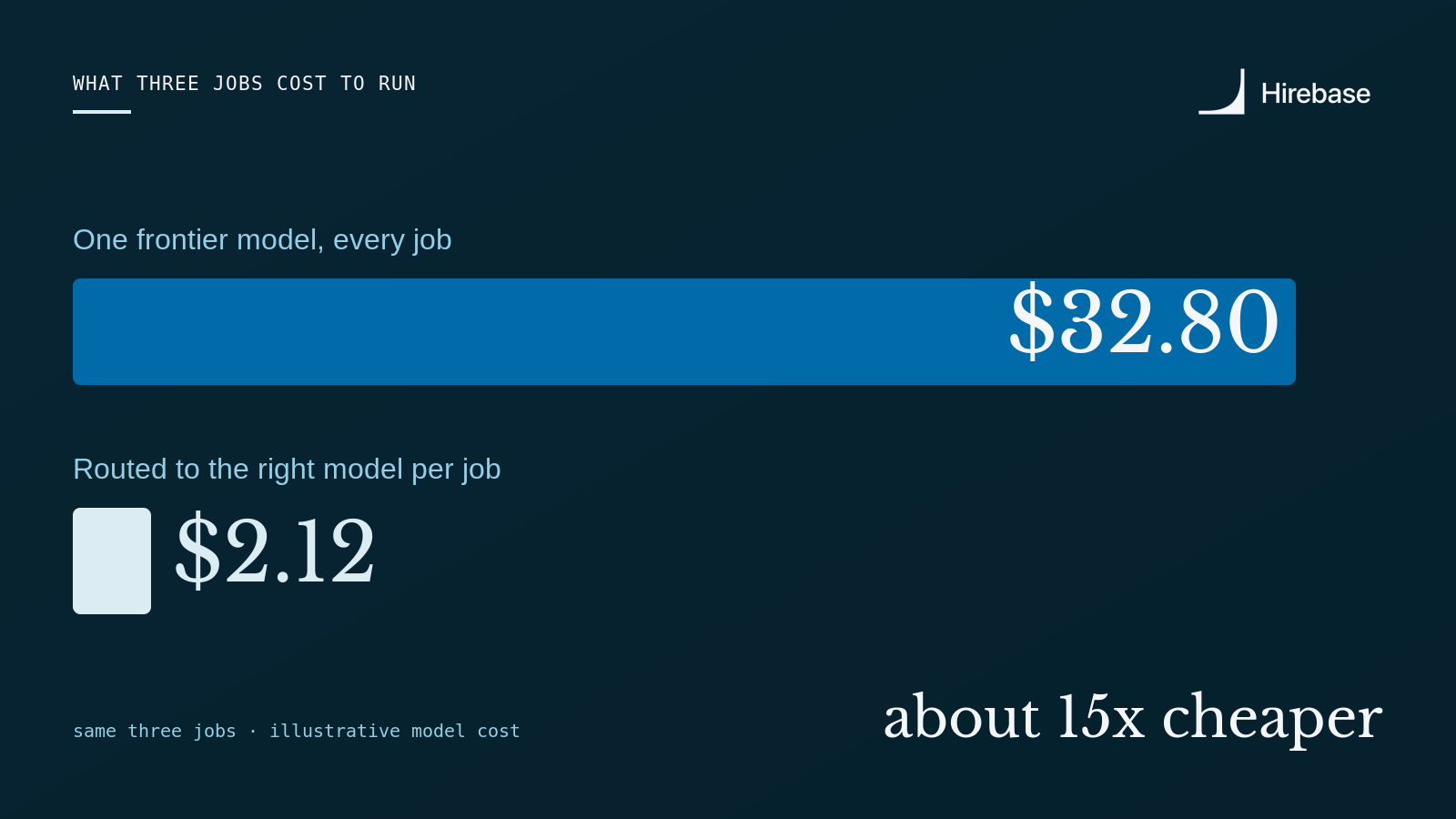
Three jobs on one frontier model vs. routed - about 15x.
The method, stated plainly
We estimated the tokens it takes to complete each job the way an AI coworker actually does it: not one clean prompt, but many calls, accumulating context, drafting and revising. Then we priced those token volumes against current published rates (June 2026):
Frontier: Claude Opus 4.8 at $5 / $25 per million tokens (input / output); GPT-5.5 at $5 / $30.
Open weight: GLM-5, the 744B open model that rivals closed frontier on reasoning, at $1.00 / $3.20; DeepSeek V4-Pro at $0.435 / $0.87; DeepSeek V4-Flash at $0.14 / $0.28; a mid open weight model (Llama-class), served, at roughly $0.20 / $0.60.
A note on the open-weight rows.
We serve these models ourselves. Open weights mean we run them on our own infrastructure instead of paying the lab that trained them, so the numbers you see are representative serving costs, not vendor pricing.
This is also why the model's country of origin is irrelevant here. An open model runs where we put it. Your data stays where we put it. There's no API call leaving the building.
The token counts are estimates, and we've laid them out transparently below. Cut them in half or double them, the conclusion doesn't budge. The gap we're measuring is more than 10x wide.
This is cost basis, not a price sheet. It's what the work costs to run.
Three jobs, six ways to pay for them
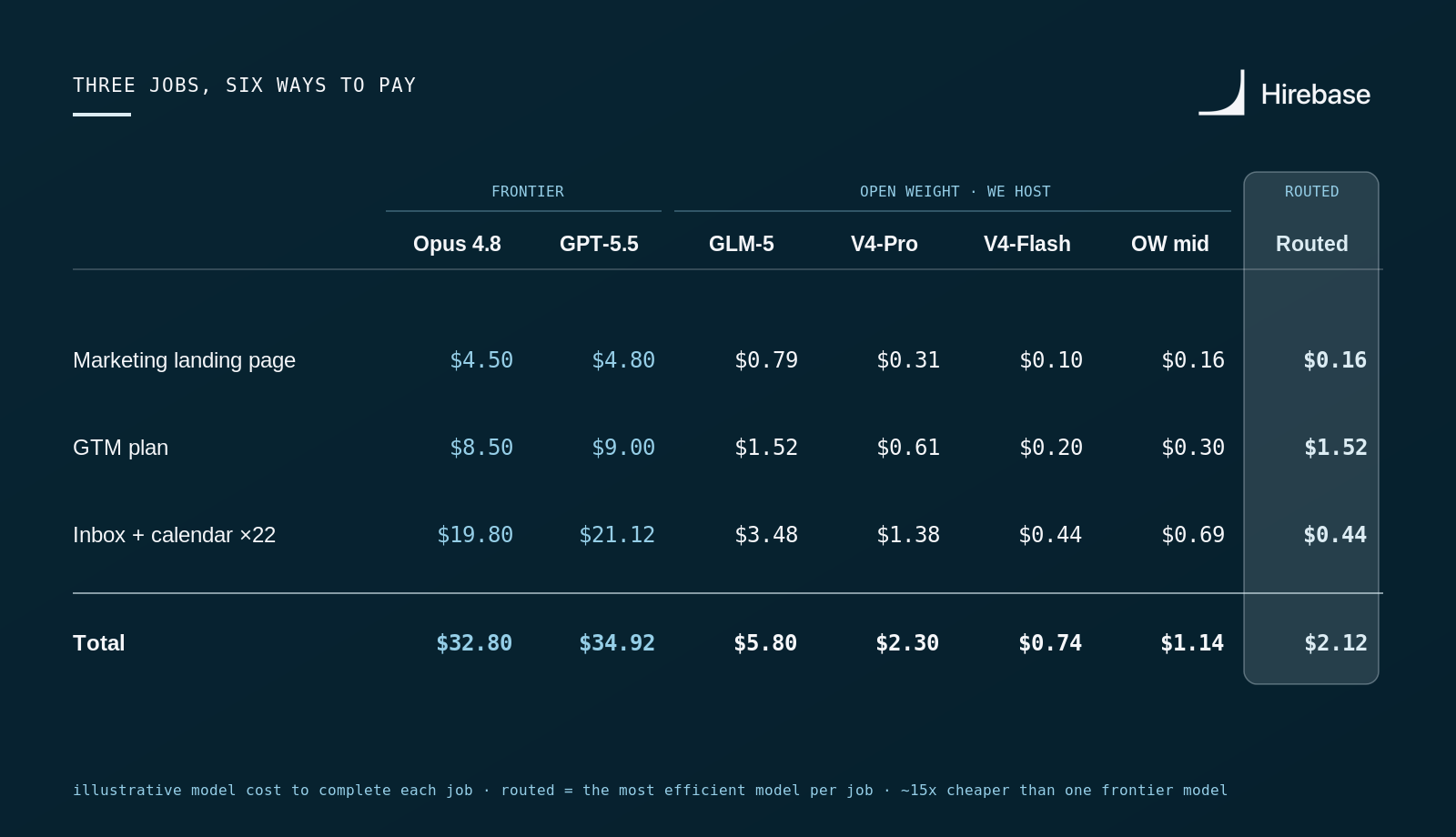
Token assumptions: landing page ≈ 600K input / 60K output; GTM plan ≈ 1.2M / 100K; daily inbox-and-calendar triage ≈ 120K / 12K per day, run across 22 workdays. Rates as published June 2026.
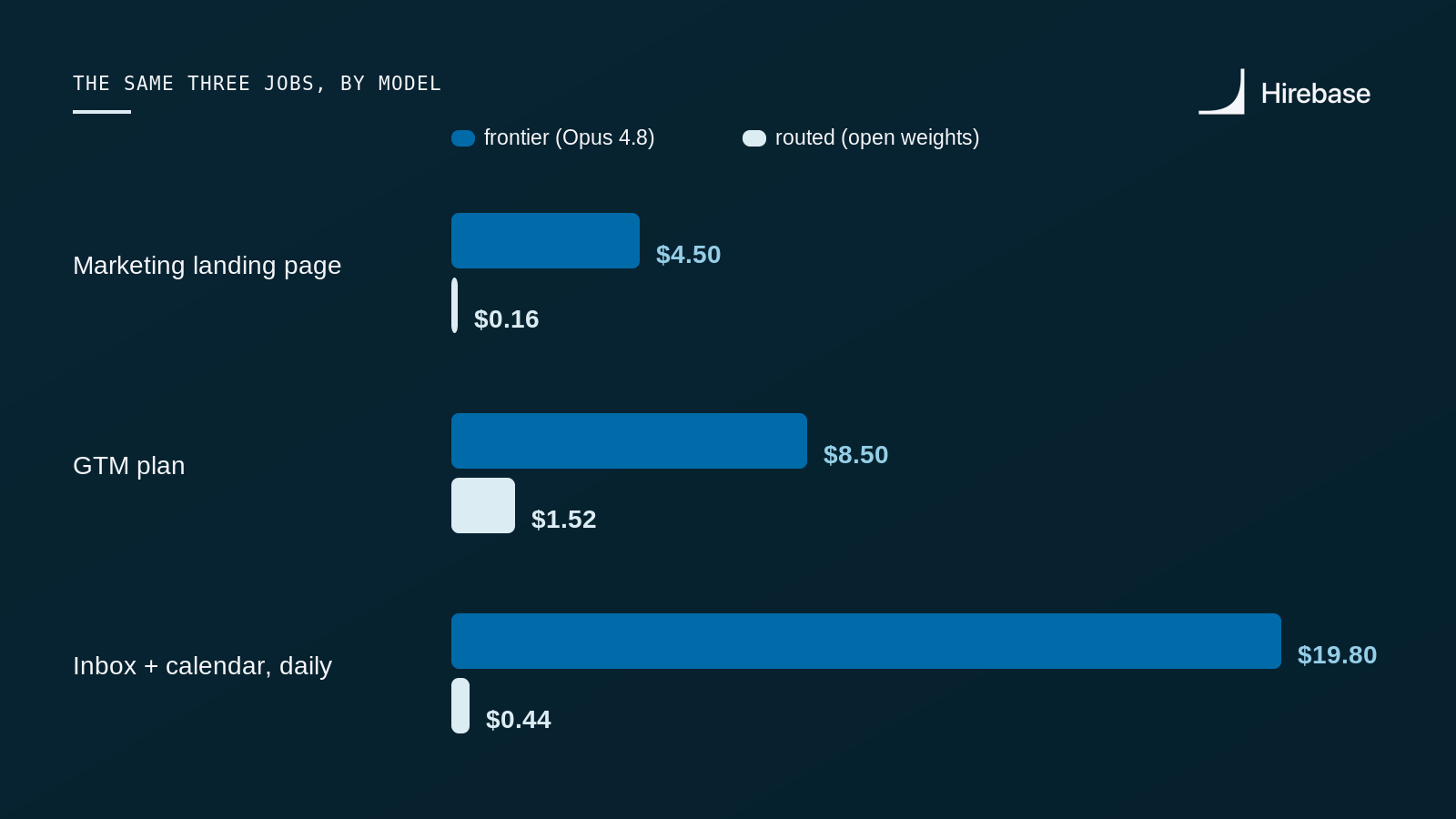
The same three jobs, frontier vs. routed open weights.
Run all three jobs on a single frontier model and you're looking at roughly $33 to $35. Route each job to the model that clears it most efficiently, and send the reasoning-heavy GTM plan to GLM‑5, a 744B open model that rivals closed frontier, and the same work costs about $2.12. That is roughly a 15× difference for output a reviewer would struggle to tell apart, and it's the conservative version: we're paying up for a frontier-class model on the one job that warrants it, not cutting the corner.
The cheapest model isn't the answer either
Look closely at the routed column and you'll notice it is not the lowest number on the board. Running everything on V4-Flash would be cheaper still, at $0.74. We didn't do that, on purpose.
You don't draft a go-to-market plan on the cheapest available model. The GTM plan is reasoning-heavy, so it goes to GLM-5 - a 744B open model that goes toe-to-toe with closed frontier - where the quality of the thinking actually matters, at $1.52 instead of the $8.50 a closed frontier model would charge for the same job. (DeepSeek V4-Pro would do it for $0.61 if you wanted to push the cost down further; we route up to GLM-5 because the plan is the one job where the extra reasoning earns its keep.) Landing-page copy goes to a capable mid open weight model. Sorting an inbox and laying out a calendar is routine classification, so it goes to the fastest, cheapest model that does it reliably (V4-Flash).
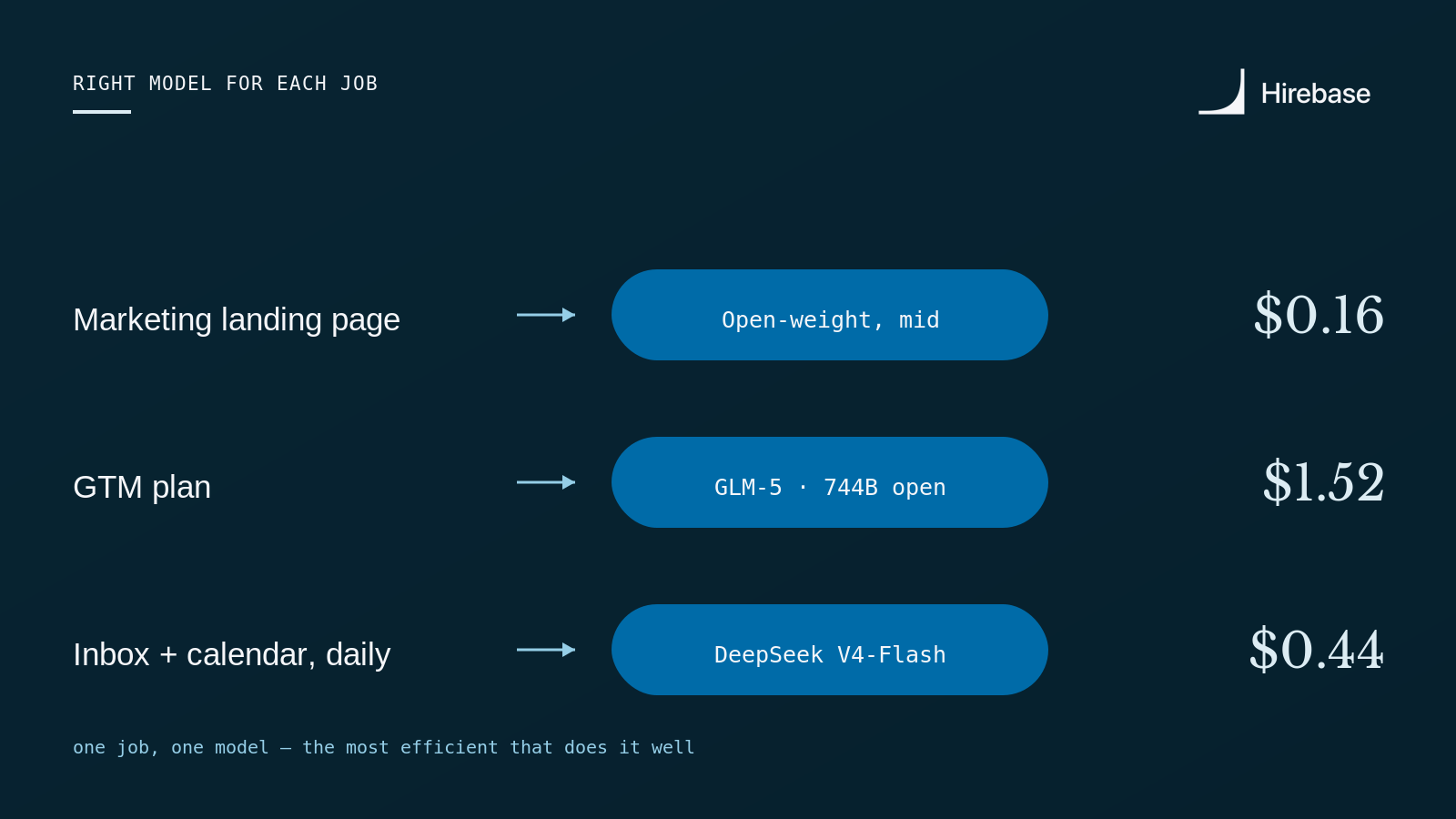
Each job routed to the most efficient model that does it well.
Fit is everything. Undersize the model and the difficult work collapses; oversize it and you're paying frontier prices for tasks a much humbler one could have finished without breaking a sweat.
This is the maneuver a single-model architecture cannot execute, whether that model sits at the frontier or the bargain tier. The moment you bind every task to one engine, you are either spending too much for the mundane or risking too little on the critical. The savings live in the routing.
Why open weights set the floor
Every efficient option in this table is an open weight model, and that is no accident. A frontier lab must price each token to amortize the cost of training a flagship, operate at margin, and finance the next generation. An open weight model need only cover the cost of inference and a reasonable return. These are fundamentally different economics, and the open weight equation has a lower floor by construction. Because the weights are open, BasedAPIs serves them at that floor on infrastructure we control, with no rent to pay the originator.
This is why the cheap column is not a promotional price waiting to snap back. When DeepSeek made its 75% cut permanent at the end of May, it was pricing at the level its cost structure already sustains. The capability gap that once justified the frontier premium has largely closed on the work most businesses actually run. What remains is a price gap, and a price gap anchored in cost structure does not close from the expensive side.
Where this leaves Hirebase pricing
Two forces make the work affordable, and they are the two halves of that table.
First, we are not bound to one model. Every job an AI coworker does is routed to the most efficient model that can do it well, frontier-grade where it earns its keep, a cheap open model where it doesn't. Second, the efficient options are open weights, which rest on a structurally lower floor than any closed rate card.
That is the cost basis. In practice it arrives as a simple monthly plan with credits included and a balance you can see at any time. No per-seat games. No metering you discover only on the invoice. Because the work underneath is routed and runs on open weights, those credits stretch across far more finished jobs than the same spend would buy at frontier rates. (For developers and teams who want this routing as raw infrastructure rather than finished work, that's BasedAPIs, open weight models served reliably for production workloads, coming soon.)
But routing only matters because the rest is handled. A cheap token is worthless if the agent breaks on an expired OAuth token before it finishes the job, which is how most do-it-yourself deployments actually fail. The numbers above are only the model usage. What Hirebase delivers, and prices, is the whole job done start to finish: every connection to the tools you already use, the workflow that carries it from brief to reviewed output, and the stack underneath kept standing. You are not buying tokens. You are buying finished work, plumbing included.
One more thing worth saying plainly. Because we host the open weights ourselves, the work runs on infrastructure we control. Your data remains yours. It is never sent to the lab that trained the model, and it is never fed back to train the next one.
One last thing the table cannot show. None of this is about replacing the person who would otherwise do the work. It is about removing the landing-page draft, the first-pass GTM research, the daily inbox triage from their plate for roughly a dollar, so they can spend their day on the judgment no model can substitute for.
If you have been quoted frontier-model economics for work that does not require a frontier model, see what the same work costs when it is routed and handled for you. The closed beta is open. Pricing is transparent and fair. No per-seat games.
Hirebase is a product of BasedAI, the acceleration and commercialization layer for open source AI. Enterprise versions of Hirebase are coming soon.